Debate Content, Part II
The prior post on debate content didn’t suggest much policy or issue-oriented actual debate. Nevertheless, here’s one last attempt to get at the substance of the presidential election debates.
I’m starting by estimating a mixed membership clustering algorithm, a topic model, to see if identifiable topics arise from the word usage in the debates. The structural topic model, provided in the stm package, will estimate a chosen number of topics, provide the document proportions for each topic, and the word probabilities for each topic. Let’s look at some of those. As before, the full script is on GitHub.
rm(list=ls())
rm(list=ls())
library(tidyverse)
library(quanteda)
library(stm)
setwd("../../../dataForDemocracy/debate2016analysis/")
load("debateTopics.RData") I loaded the image file created from running the code in this post; the model takes a little time to run and I want to call the already generated results. Still, here are the steps to set up the model:
# extract docvars to be converted to stm format
debateDocVars <- docvars(debate16corpus)
debateDocVars$speech <- debates16$speech
# define words to remove, stopwords (except for pronouns) and moderators
moderators <- c("chris", "anderson", "martha", "lester", "elaine")
otherStop("applause", "laughter", "crosstalk", "laughther")
debatedfm <- dfm(debate16corpus,
remove = c(stopwords("english"), moderators, otherStop),
remove_punct = TRUE,
stem = TRUE)
debatedfm <- dfm_trim(debatedfm, min_count = 2) # remove words that occur less than twice to reduce the sparsity of the document-feature matrix
# put text in format for stm
debOut <- convert(debatedfm, to = "stm",
docvars = debateDocVars)Now I’m ready to estimate a topic model. The stm package has some lovely built-in functions for exploring reasonable values of k (the number of topics), so I use those:
# searchK estimates topic exclusivity, coherence; model likelihood, residuals for each k
debEval <- searchK(debOut$documents, debOut$vocab, K = seq(10,75,5),
prevalence = ~ as.factor(party) + as.factor(season),
data = debOut$meta, init.type = "Spectral")
plot(debEval) # I like k = 25
# estimate the stm with k=25 and document covariates "party" and "season"
debFit25 <- stm(debOut$documents, debOut$vocab, K = 25,
prevalence = ~ as.factor(party) + as.factor(season), max.em.its = 75,
data = debOut$meta, init.type = "Spectral")Let’s look at some of the results.
# Topic quality
topicQuality(debFit25, debOut$documents)## [1] -0.9824357 -2.9826774 -37.7944197 -1.5247543 0.0000000
## [6] -0.8183922 -2.8966792 -1.9480848 -0.2806321 -13.7256466
## [11] 0.0000000 -0.2455531 0.0000000 0.0000000 0.0000000
## [16] -1.9480848 -3.3426760 -0.2806321 -2.1524068 0.0000000
## [21] -1.2279887 -3.9737125 -1.9068538 -4.7999493 -0.1753950
## [1] 9.536139 9.490152 9.071752 9.514851 9.439077 9.296100 9.463318
## [8] 7.982224 9.283193 9.006190 9.177255 8.995309 7.923418 8.958047
## [15] 8.829528 8.779281 8.519666 8.876857 8.665832 8.652728 8.065749
## [22] 8.597652 7.931563 8.548277 8.791430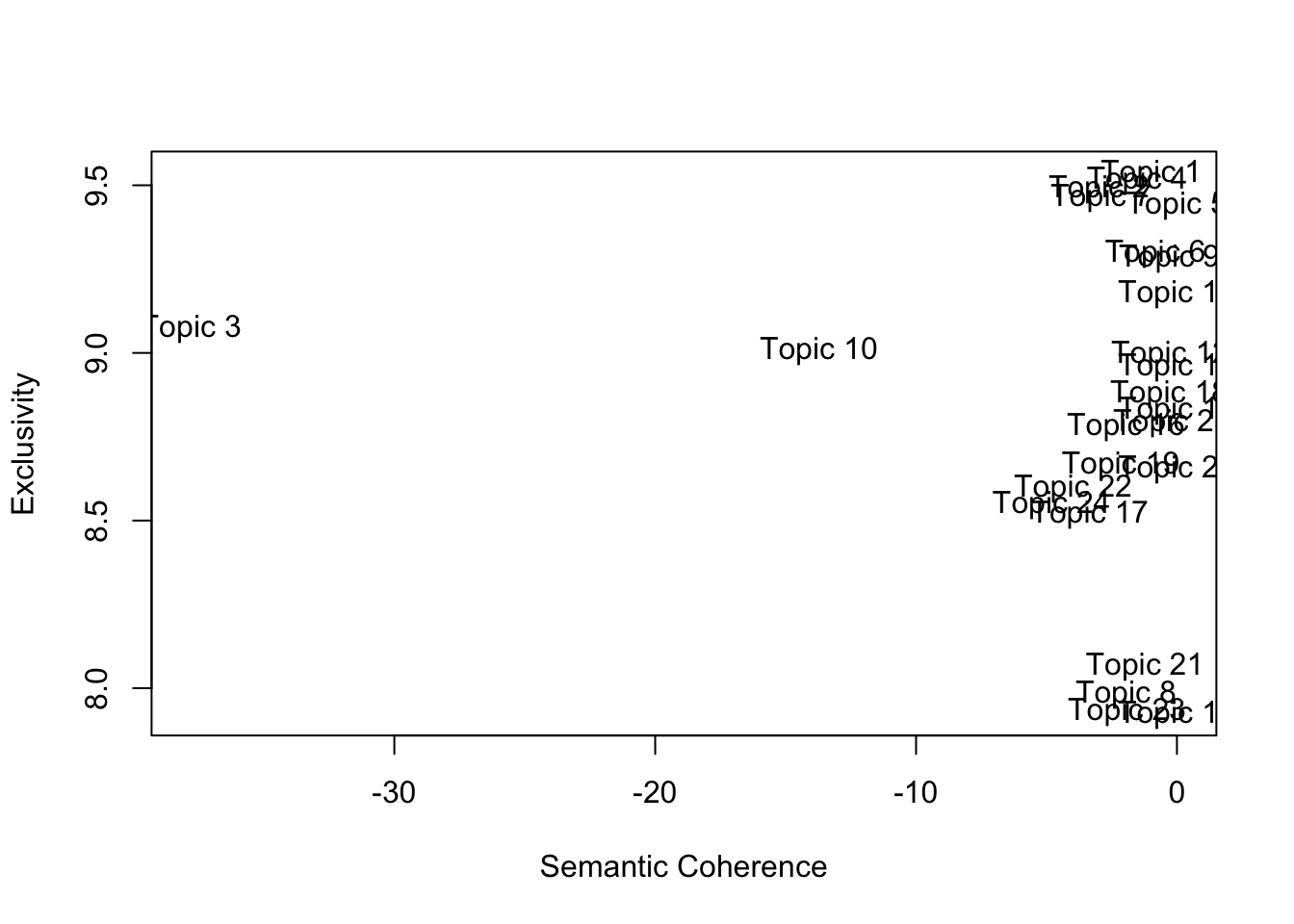 This plots the exclusivity of each topic by the coherence of each topic. By coherence, we mean that high-probability words for the topic tend to co-occur within documents. More positive values (or less negative values) indicate more coherent topics.
This plots the exclusivity of each topic by the coherence of each topic. By coherence, we mean that high-probability words for the topic tend to co-occur within documents. More positive values (or less negative values) indicate more coherent topics.
By exclusivity, we mean that the top words for a topic are unlikely to appear as a top word of the other topics; if words with high probability under topic 1 have low probabilities under other topics, then we say that topic 1 is exclusive.
Topic 3 scores particularly low on coherence, Topic 10 is relatively low as well; Topics 13, 23, and 8 score relatively low on exclusivity.
# Topic prevalence
plot(debFit25, type = "summary", labeltype="frex") Based on the 25 topics the model generates, the most common themes across the primary and general election season debates were those captured in Topics 8, 13, 21, and 23 – which were also less exclusive topics.
Based on the 25 topics the model generates, the most common themes across the primary and general election season debates were those captured in Topics 8, 13, 21, and 23 – which were also less exclusive topics.
What are these topics? The topic prevlance plot provides three heavily-associated words, which is a common approach for generating a sense of the topic substance. But there are multiple ways of thinking about what words are associated with a topic.
# Topic top words
labelTopics(debFit25)## Topic 1 Top Words:
## Highest Prob: go, countri, peopl, deal, back, come, like
## FREX: advantag, oil, ever, nobodi, ukrain, econom, discuss
## Lift: 1.5, ike, manipul, blew, dwight, eisenhow, imbal
## Score: 1.5, manipul, blew, ukrain, ike, advantag, currenc
## Topic 2 Top Words:
## Highest Prob: peopl, go, think, isi, just, talk, countri
## FREX: internet, jeb, isi, fight, tough, mastermind, wish
## Lift: isis.w, unprofession, weaker, mastermind, disservic, warrior, internet
## Score: jeb, isis.w, internet, mastermind, isi, brilliant, unprofession
## Topic 3 Top Words:
## Highest Prob: trump, donald, said, hillari, governor, work, clinton
## FREX: penc, vladimir, trump, donald, governor, virginia, fire
## Lift: barbara, bond, castil, cathol, compon, councilman, disclos
## Score: penc, donald, hillari, vladimir, governor, virginia, barbara
## Topic 4 Top Words:
## Highest Prob: go, peopl, know, can, right, countri, come
## FREX: nasti, bankruptci, legal, three, gun-fre, atlant, nice
## Lift: gun-fre, superpac, kudlow, dishonesti, lucki, nasti, out.i
## Score: superpac, nasti, bankruptci, gun-fre, atlant, dynam, legal
## Topic 5 Top Words:
## Highest Prob: say, want, go, countri, peopl, like, know
## FREX: sound, timer, abort, total, win, atlant, border
## Lift: timer, bergdahl, lender, unidentifi, evolv, concept, wed
## Score: bergdahl, timer, sound, atlant, evolv, bankrupt, pro-lif
## Topic 6 Top Words:
## Highest Prob: peopl, go, china, get, look, said, say
## FREX: china, angri, field, inaud, bomb, devalu, friend
## Lift: caterpillar, field, kamatsu, tariff, 2nd, cleanup, indonesia
## Score: 2nd, angri, field, tractor, inaud, boe, nikki
## Topic 7 Top Words:
## Highest Prob: go, peopl, want, countri, get, deal, win
## FREX: domain, emin, conserv, win, pipelin, keyston, properti
## Lift: galvan, jame, necess, assumpt, atmospher, foley, josh
## Score: domain, emin, assumpt, conserv, pipelin, keyston, tremend
## Topic 8 Top Words:
## Highest Prob: think, know, get, go, peopl, can, want
## FREX: progress, sander, agenda, tri, agreement, disagr, communiti
## Lift: afghan, chuck, rachel, 2002, 2016, advocaci, assess
## Score: progress, sander, support, american, senat, constitu, tri
## Topic 9 Top Words:
## Highest Prob: go, say, peopl, just, want, tell, said
## FREX: listen, lie, jeb, florida, spent, bush, mistak
## Lift: 44, mitch, o.k, profan, none, languag, carrier
## Score: jeb, mitch, emin, domain, lie, o.k, florida
## Topic 10 Top Words:
## Highest Prob: clinton, go, hillari, state, trump, senat, donald
## FREX: kain, foreign, clinton, enforc, hillari, indiana, foundat
## Lift: reset, stifl, avalanch, beneath, boycot, cent, conjur
## Score: kain, hillari, clinton, donald, american, foreign, enforc
## Topic 11 Top Words:
## Highest Prob: think, say, peopl, go, countri, know, now
## FREX: along, babi, car, scholar, atlant, sit, 200
## Lift: 14th, 2.2, assimil, autism, english, lucent, misunderstand
## Score: 2.2, babi, atlant, scholar, jeb, car, 14th
## Topic 12 Top Words:
## Highest Prob: peopl, go, said, say, get, know, one
## FREX: poll, marco, wrong, flexibl, beat, case, cnn
## Lift: 49, 98, cloth, con, dogcatch, klu, lightweight
## Score: 49, poll, flexibl, marco, beat, bid, settl
## Topic 13 Top Words:
## Highest Prob: think, go, know, peopl, get, need, well
## FREX: coalit, ground, colleg, libyan, join, gadhafi, advoc
## Lift: marijuana, de-conflict, demon, denmark, dislodg, glitch, inquiri
## Score: coalit, denmark, issu, ground, libyan, american, colleg
## Topic 14 Top Words:
## Highest Prob: go, peopl, deal, want, know, think, countri
## FREX: larg, deal, bid, negoti, ted, endors, knock
## Lift: behav, charter, crowd, h1b, jeff, jewish, rampant
## Score: charter, bid, behav, ted, larg, pro-israel, pac
## Topic 15 Top Words:
## Highest Prob: go, peopl, get, know, just, say, one
## FREX: audit, won, hire, israel, watch, hispan, competit
## Lift: arrará, award, record-set, 2,000, 38, 46, hood
## Score: audit, 2,000, hire, won, ted, arrará, bell
## Topic 16 Top Words:
## Highest Prob: know, get, go, presid, work, think, peopl
## FREX: inequ, muslim, togeth, ground, valu, hi, tri
## Lift: hi, poetri, backward, conveni, discourag, gosh, minneapoli
## Score: inequ, backward, hi, issu, muslim, partisan, poetri
## Topic 17 Top Words:
## Highest Prob: go, peopl, think, well, support, get, know
## FREX: water, auto, flint, industri, michigan, lead, export
## Lift: airbus, carrot, export-import, naacp, repair, resign, s
## Score: auto, water, flint, airbus, support, michigan, gun
## Topic 18 Top Words:
## Highest Prob: go, peopl, want, countri, say, get, know
## FREX: mosul, amend, putin, fiction, outsmart, nafta, 6
## Lift: fame, fiction, outsmart, fisher, four-star, outplay, podesta
## Score: mosul, fisher, fiction, outsmart, hillari, nafta, amend
## Topic 19 Top Words:
## Highest Prob: want, peopl, think, get, go, donald, work
## FREX: court, suprem, russian, donald, children, insur, parent
## Lift: devot, energy-independ, ethiopia, ordinari, marriag, 4-year-old, dug
## Score: donald, devot, suprem, insur, russian, children, classifi
## Topic 20 Top Words:
## Highest Prob: go, countri, look, think, say, thing, said
## FREX: secretari, list, sean, audit, communiti, releas, nato
## Lift: 4,000, certif, defect, estat, fed, mainstream, 1st
## Score: secretari, 1st, sean, hanniti, audit, nafta, fed
## Topic 21 Top Words:
## Highest Prob: think, go, peopl, well, can, know, presid
## FREX: o, dodd-frank, region, afford, young, basic, act
## Lift: 92, alan, campus, gaddafi, grandpar, index, jihadi
## Score: 92, o, sander, afford, dodd-frank, gun, region
## Topic 22 Top Words:
## Highest Prob: peopl, think, presid, can, know, senat, go
## FREX: comprehens, deport, reform, immigr, vote, rescu, sander
## Lift: asylum, congresswoman, daca, dapa, fenc, immigrants.so, indefinit
## Score: comprehens, congresswoman, deport, reform, rescu, sander, karen
## Topic 23 Top Words:
## Highest Prob: go, think, well, peopl, know, donald, make
## FREX: donald, wealthi, propos, undocu, invest, debt, kind
## Lift: birther, draperi, fabric, incomes.i, ineffect, mutual, slash
## Score: donald, birther, propos, wealthi, american, gun, polic
## Topic 24 Top Words:
## Highest Prob: presid, peopl, senat, go, support, think, new
## FREX: york, sander, barrier, palestinian, support, senat, set
## Lift: 195, 7.25, abba, connecticut, daili, diagnosi, distract
## Score: sander, support, 195, palestinian, barrier, senat, cheer
## Topic 25 Top Words:
## Highest Prob: go, peopl, know, countri, say, look, thing
## FREX: inner, hillari, lie, allow, e-mail, disast, judgment
## Lift: 600, abe, acid, awak, compliment, deborah, furious
## Score: 600, hillari, inner, lie, subpoena, delet, mosulThe labelTopics function gives us some options, including the highest probability words, or those that appear most frequently in the topic. But those really frequent words tend to appear in multiple topics. Instead, I like the FREX, or frequency-exclusivity weighted word lists. Honestly, this is one of less intuitive set of topics I’ve seen. Topic 7 (eminent domain, keystone pipeline) I recall coming up in the debates; Topic 17 is clearly Michigan-related – the water crisis, the auto industry; Topic 22 looks to be aobut immigration reform. But many of these look like a jumble.
While to really get at this would require additional iteration, I’m inclined to believe that the debates were, in fact, composed of many random streams of rhetoric. Not one of our most laudable civic moments. Still, the LDAvis package can generate a fun dynamic visualization of topic models, so I tried it out.
library(LDAvis)
library(servr)
toLDAvis(mod=debFit25, docs=debOut$documents, R=20, out.dir = "debatesLDAvis", open.browser = FALSE) # generates a webpageYou can see the resulting visualization here.
# Topic prevalence by debate: put topic proportions in a data frame
debateTopics <- as.data.frame(debFit25$theta)
debateTopics <- cbind(debateTopics, debates16)
# reshape the data frame
topicsLong <- debateTopics %>%
select(V1:V25, date, party) %>%
gather(topic, value, -date, -party)
# and graph the topics for the four general election debates
topicsLongGeneral <- topicsLong %>% filter(date>as.Date("2016-09-01"))
p <- ggplot(topicsLongGeneral, aes(x=topic, y=value, fill=party))
p + geom_bar(stat="identity") + facet_wrap(~date) +
scale_fill_manual(values=c("blue3", "orange3")) In this case, each candidate’s rhetoric is dominated by a single topic, which changes from debate to debate. I find this plausible (that the candidates were talking past each other, and responding to different pressures as the campaign wore on), but this clearly needs some further iterations to pin down fully.
In this case, each candidate’s rhetoric is dominated by a single topic, which changes from debate to debate. I find this plausible (that the candidates were talking past each other, and responding to different pressures as the campaign wore on), but this clearly needs some further iterations to pin down fully.